
Infoworks: The Quantum Leap of Analytics Infused with Data Engineering Agility

Buno Pati , Chairman of the Board
Infoworks is the only solution provider with an end-to-end solution stack that delivers the necessary level of automation to hide big data complexity and deliver the process agility needed to empower almost any company to harness their data as effectively as the big data-driven giants.
“The introduction of data engineering agility into the big data analytics market has progressed in similar fashion to the introduction of the television back in the early 50s. When television was first evolving, broadcasters did not initially understand the opportunity to deliver a completely new form of entertainment,” recalls Buno Pati, Chairman of the Board of Infoworks—provider of a unique big data software platform that delivers data engineering agility by automating the creation and ongoing operation of big data pipelines and workflows from source to consumption.
“Like TV’s earliest days, the level of automation available in data analytics has increased an order of magnitude from the data warehouse world to the big data world, but companies are only now starting to realize how they can leverage this change for their competitive advantage. The reality is that people learn over time,” Pati says.
Easing its Way into Data Analytics
“Infoworks’ origin and entry into the big data space is quite unique,” explains Pati.
The journey started ten years ago, when Google was running its own analytics on a traditional data warehouse system and technology. They realized the inadequacies of this system against a continuously growing volume of data and that operating all the data integration and analytics processes manually was becoming nearly impossible. Amar Arsikere, who was working at Google at the time and later co-founded Infoworks, moved Google from a legacy analytics stack to what was then a new big data platform, Google BigTable.
"We are truly a horizontal solution. Every company and industry in the world is eagerly trying to harness their data for competitive advantage. As a result, our solution is not restricted to any single vertical"
Arsikere built a data warehousing platform on BigTable at Google, automating its data analytics pipelines and workflow. This platform successfully replaced their legacy Informatica, Oracle, Microstrategy, and QlikView technology stack and introduced a new level of agility and automation that transformed the entire technical landscape. Following this innovation, Arsikere went to Zynga, where he built their gaming database. Arsikere created a “version two” of his agile data engineering platform—a substantial in-memory database infrastructure for the multimillion-dollar gaming operation. After successfully building these big data engineering agility platforms for Google and Zynga, it became clear that other organizations interested in taking advantage of big data analytics would also benefit greatly from an equivalent degree of data engineering agility capabilities.
“The big deal about all of these ‘born-digital’ type companies is the advanced level of agility they have achieved with their data and analytics that more traditional companies have not been able to accomplish,” says Pati. “The massive opportunity to help more traditional organizations close this analytics gap, achieve a new level of data agility, and harness their data as effectively as Google, Facebook and Amazon led to the inception of Infoworks.”
“Our competitors only automate a part of the process, which leaves a significant amount of integration work for their customers. The problem can only be truly solved by automating the entire process and workflow end-to-end,” reasons Pati. “Organizations that attempt to piece together ‘best-in-class’ point solutions have to then create their own integration layer, which they have to maintain and support themselves, consuming time and resources.”
Infoworks is offering the market a solution that takes advantage of their founder’s learning from past experiences as well as their more current customer experiences and incorporates that learning into a platform offered to the broader market. Infoworks’ platform, in a true sense, is the only end-to-end automated software platform for “agile data engineering” currently available in the market.
Process of Delivery
Infoworks’ platform automates data pipelines and workflows for a variety of organizations, regardless of industry, swiftly meeting changing data and analytics requirements—without weighing down the IT department of these companies or requiring an army of big data or Hadoop developers and consultants. “Our extremely high level of data engineering agility and automation eliminates a lot of the manual process. When we engage with a new customer, generally they would budget three months for their proof of concept. However, we deliver that same value within five days or less,” says Pati. “With Infoworks’ solutions, organizations have progressed from implementing only two or three business intelligence and reporting big data use cases a year to delivering one every three weeks.”
Infoworks deploys an agile end-to-end data engineering platform that automates almost the entire process starting with crawling data sources to identify the data types and gathering other metadata it uses to efficiently ingest large volumes of data at high speed onto a big data platform either on-premises or in the cloud. “Not only do we bring the data over; we keep it fresh. When the data changes in the source, we identify those changes automatically and propagate both new rows and new columns of data into the data lake. Our customers can be running any commercial version of Hadoop or running on Azure, AWS or Google Cloud. We make it easy for them regardless of the underlying big data architecture they select,” says Pati.
The complete solution tracks and captures changing data from the sources, transforming the data and generating high performance data interfaces that deliver sub-second query times for data visualization tools like Tableau. It also orchestrates production data flows, ensuring system uptime by starting, stopping and restarting system processes while monitoring the status of the production environment.
Infoworks was founded on the idea that data engineering agility delivered through increased automation would be the core enabler used to eliminate the hand-coding that most organizations currently use as they squander precious time and engineering talent by manually creating big data workflows. Another approach companies currently take is the use of point tools that automate only a subset of the overall data engineering process, requiring them to fill in the gaps between tools with their own hand-coded integration. Infoworks addresses the entire data engineering process from source to consumption, which gives them an edge over all other solution providers in the market.The core value proposition of Infoworks is to deliver the agility needed to empower all companies to harness their data as effectively as the data-driven market giants
“Our competitors only automate a part of the process, which leaves a significant amount of integration work for their customers. The problem can only be truly solved by automating the entire process and workflow end-to-end,” reasons Pati. “Organizations that attempt to piece together ‘best-in-class’ point solutions have to then create their own integration layer, which they have to maintain and support themselves, consuming time and resources.”
Infoworks is offering the market a solution that takes advantage of their founder’s learning from past experiences as well as their more current customer experiences and incorporates that learning into a platform offered to the broader market. Infoworks’ platform, in a true sense, is the only end-to-end automated software platform for “agile data engineering” currently available in the market.
Process of Delivery
Infoworks’ platform automates data pipelines and workflows for a variety of organizations, regardless of industry, swiftly meeting changing data and analytics requirements—without weighing down the IT department of these companies or requiring an army of big data or Hadoop developers and consultants. “Our extremely high level of data engineering agility and automation eliminates a lot of the manual process. When we engage with a new customer, generally they would budget three months for their proof of concept. However, we deliver that same value within five days or less,” says Pati. “With Infoworks’ solutions, organizations have progressed from implementing only two or three business intelligence and reporting big data use cases a year to delivering one every three weeks.”
Infoworks deploys an agile end-to-end data engineering platform that automates almost the entire process starting with crawling data sources to identify the data types and gathering other metadata it uses to efficiently ingest large volumes of data at high speed onto a big data platform either on-premises or in the cloud. “Not only do we bring the data over; we keep it fresh. When the data changes in the source, we identify those changes automatically and propagate both new rows and new columns of data into the data lake. Our customers can be running any commercial version of Hadoop or running on Azure, AWS or Google Cloud. We make it easy for them regardless of the underlying big data architecture they select,” says Pati.
The complete solution tracks and captures changing data from the sources, transforming the data and generating high performance data interfaces that deliver sub-second query times for data visualization tools like Tableau. It also orchestrates production data flows, ensuring system uptime by starting, stopping and restarting system processes while monitoring the status of the production environment.
The solution helps clients govern their data, including tracking lineage, controlling data access and masking data to ensure proper privacy. The Infoworks system creates data pipelines, which transform and combine the data uniquely, ultimately generating a set of in-memory data models called “cubes” that are consumable by business and analytics applications.
“This entire pathway has historically been addressed piece by piece, which then required manual coding to stitch the pieces together. We treat it as a whole and automate the entire workflow,” says Pati. According to Infoworks, their platform automates both the development process and the operational management of data pipelines while competitors focus mainly on development of new data pipelines and leave the operationalization as an exercise customers must perform themselves. The resulting challenge is that as organizations add more data pipelines, their engineering resources have to shift from developing new data pipelines and analytics to manually managing those pipelines until they no longer have engineering resources available. Because Infoworks manages the promotion of development into production and then automates the orchestration and management of the production pipelines, their customers can scale both in terms of their ability to develop new data analytics use cases as well as manage them in production. “The perspective we take is much more holistic, providing a great deal more agility then what existed before because we are automating the end-to-end process both for the development and operationalization of big data engineering projects,” explains Pati.
Infoworks’ solutions address the creation of big data business intelligence and analytics workflows, but they also automate the migration of legacy data warehouses into a big data environment as well as help customers automate the creation of data lakes both on-premises and in the cloud.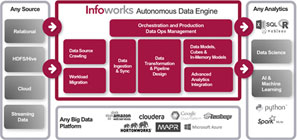 Fields of Operation
Fields of Operation
“We are truly a horizontal solution,” notes Pati. “Every company and industry in the world is eagerly trying to harness their data for competitive advantage. As a result, our solution is not restricted to any single vertical.” Nevertheless, there are a handful of verticals where Infoworks has observed repeated data patterns and is moving towards “templatizing” data pipelines for specific vertical markets. One example is the oil and gas industry where a common set of data pipelines and embedded data sources can be reused by multiple organizations. For this market, Infoworks is creating add-on components that are market specific and accelerate customer implementation even further. The result is that Infoworks data engineering agility and automation is allowing their customers get new analytics pipelines up and running within two to three weeks while only requiring one or two data engineers. This significantly reduces the development efforts for similar projects, which previously took months of effort and ten or more data engineers and data scientists.
A Triumphant Venture of a Young Company
With its unique software solutions and successful Fortune 500 customer implementations, Infoworks caters to clients worldwide, providing what the company calls unmatched quality and reliability. Over the next two to three years, the Infoworks team is committed to enhancing and developing its solutions by adding more automation to further simplify the deployment of big data solutions as they to cater to their customers’ future requirements.
As with any software platform, the Infoworks platform also is a “living product” as new needs and requirements continue to drive product enhancements. The actual growth and increase in capability of the platform and its performance materialize further when customers build their own analytics and applications on top of it. “This is a relatively young company, and many huge companies are wholly dependent on Infoworks as their primary big data engineering platform. It’s a remarkable achievement for a company at this stage,” concludes Pati.
“This entire pathway has historically been addressed piece by piece, which then required manual coding to stitch the pieces together. We treat it as a whole and automate the entire workflow,” says Pati. According to Infoworks, their platform automates both the development process and the operational management of data pipelines while competitors focus mainly on development of new data pipelines and leave the operationalization as an exercise customers must perform themselves. The resulting challenge is that as organizations add more data pipelines, their engineering resources have to shift from developing new data pipelines and analytics to manually managing those pipelines until they no longer have engineering resources available. Because Infoworks manages the promotion of development into production and then automates the orchestration and management of the production pipelines, their customers can scale both in terms of their ability to develop new data analytics use cases as well as manage them in production. “The perspective we take is much more holistic, providing a great deal more agility then what existed before because we are automating the end-to-end process both for the development and operationalization of big data engineering projects,” explains Pati.
Infoworks’ solutions address the creation of big data business intelligence and analytics workflows, but they also automate the migration of legacy data warehouses into a big data environment as well as help customers automate the creation of data lakes both on-premises and in the cloud.
Fields of Operation“We are truly a horizontal solution,” notes Pati. “Every company and industry in the world is eagerly trying to harness their data for competitive advantage. As a result, our solution is not restricted to any single vertical.” Nevertheless, there are a handful of verticals where Infoworks has observed repeated data patterns and is moving towards “templatizing” data pipelines for specific vertical markets. One example is the oil and gas industry where a common set of data pipelines and embedded data sources can be reused by multiple organizations. For this market, Infoworks is creating add-on components that are market specific and accelerate customer implementation even further. The result is that Infoworks data engineering agility and automation is allowing their customers get new analytics pipelines up and running within two to three weeks while only requiring one or two data engineers. This significantly reduces the development efforts for similar projects, which previously took months of effort and ten or more data engineers and data scientists.
A Triumphant Venture of a Young Company
With its unique software solutions and successful Fortune 500 customer implementations, Infoworks caters to clients worldwide, providing what the company calls unmatched quality and reliability. Over the next two to three years, the Infoworks team is committed to enhancing and developing its solutions by adding more automation to further simplify the deployment of big data solutions as they to cater to their customers’ future requirements.
As with any software platform, the Infoworks platform also is a “living product” as new needs and requirements continue to drive product enhancements. The actual growth and increase in capability of the platform and its performance materialize further when customers build their own analytics and applications on top of it. “This is a relatively young company, and many huge companies are wholly dependent on Infoworks as their primary big data engineering platform. It’s a remarkable achievement for a company at this stage,” concludes Pati.
